Using Bright Data's scraping browser to Scrape Web Pages
There comes a time when you need to scrape a website for data. For instance, you might want to scrape a website to get the list of all the products they have or you might want to scrape a website to get the list of all the blog posts they have. Or you just want to automate the process of scraping a website for data to make your life easier.
- What is web scraping?
- Using a headless browser
- Bright Data’s scraping browser
- Using the scraping browser
- Using Bright Data’s scraping browser is ethical
- Wrapping up
What is web scraping?
But what do you mean by scraping web pages anyway?
Well, scraping web pages is the process of extracting data from a website by traversing through its HTML structure. This is usually done by using a web scraping tool or a web scraping library.
We can accomplish this by using something called a headless browser. A headless browser is a web browser that can be used without a graphical user interface. It can be controlled programmatically and is used to automate web page interaction.
So, what we do, essentially, is spin up a headless browser and then use it to navigate through the website’s HTML structure and extract the data we need.
Using a headless browser
There are a lot of headless browsers out there. But Puppeteer is the most popular one. It’s a Node.js library that provides a high-level API to control Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
You install Puppeteer in your existing JavaScript project with npm using the following command.
npm i puppeteer
Once installed, a simple script to scrape a website title would look like so.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.title();
console.log(title);
await browser.close();
})();
As you can tell, we’re using the puppeteer package to launch a headless browser and then we’re navigating to the website we want to scrape. And then, we’re extracting the title of the website.
Now, this works fine for most of the websites but in scenarios where the website you want to scrap certain websites that are protected by anti-bot measures and CAPTCHAs, you might not be able to scrape them using Puppeteer.
In such cases, you can use a scraping browser like Bright Data’s scraping browser.
Bright Data’s scraping browser
It’s a browser that’s built specifically for web scraping at scale. It’s a Chromium-based browser instance that’s built to handle anti-bot measures, fingerprints, CAPTCHAs, and more. It even bypasses the toughest website blocks.
You can also instantiate unlimited instances of the scraping browser and run them in parallel to scrape multiple websites at the same time.
This scraping browser is a “headfull” browser as opposed to Puppeteer which is a “headless” browser.
Meaning, while headless browsers are often used with proxies for data scraping, these browsers are easily detected by bot-protection software, making data scraping difficult on a large scale.
A headfull browser, on the other hand, is far superior to headless browsers for scaling data scraping projects & bypassing blocks.
Using the scraping browser
To start using Bright Data’s scraping browser, you first need to create an account on Bright Data.
Once you’ve created an account, navigate to https://brightdata.com/cp/zones and click on Get Started in the Scraping Browser section.

This will take you to the Scraping Browser page where you can create a new scraping browser instance like so.
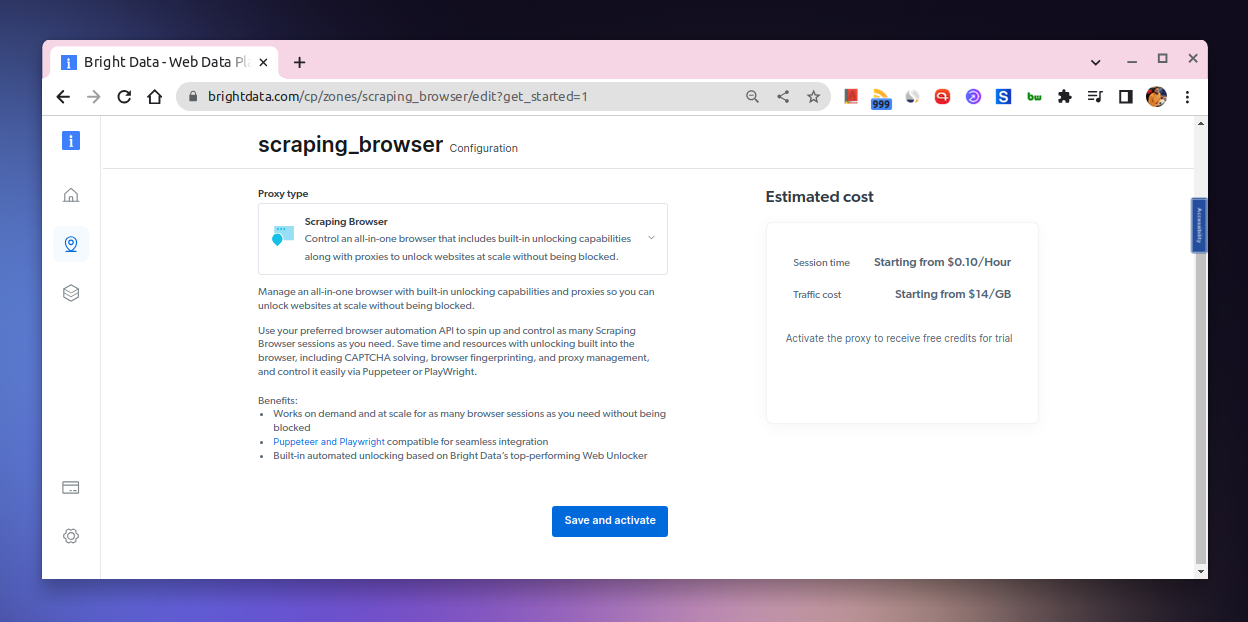
This will take you to a page from which you can get the Host, Username, and Password that you can use to instantiate the scraping browser.
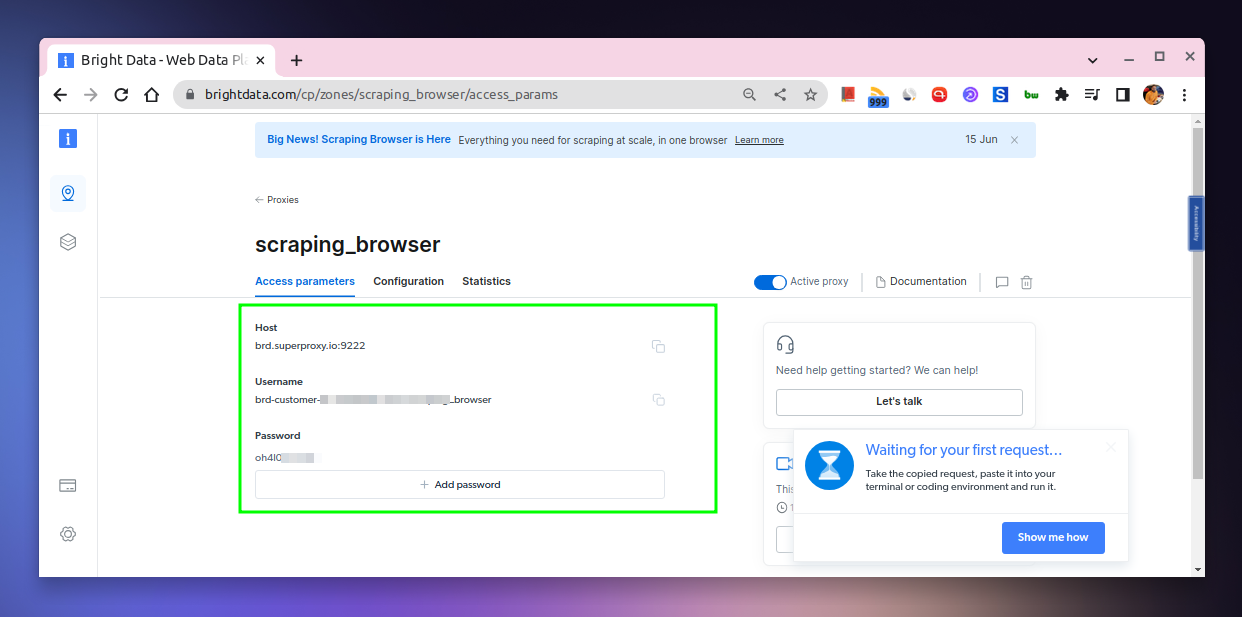
Once done, you can start using these credentials to instantiate the scraping browser using Puppeteer.
In this case, we’ll use the puppeteer-core package which is a version of Puppeteer that doesn’t download Chromium by default.
Note: Apart from Puppeteer, this scraping browser is also compatible with Playwright as well as Selenium. But we’ll stick with Puppeteer for this example.
Instead, it provides a way to launch Chromium from a specific path.
npm i puppeteer-core
And here’s how you can grab an entire website’s HTML using Bright Data’s scraping browser.
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNTID>-zone:<PASSWORD>'
const auth='USERNAME:PASSWORD';
async function scrape(){
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@brd.superproxy.io:9222`
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => {
return document.documentElement.outerHTML
});
console.log(html);
} catch(e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main==module)
scrape();
Save it as scrape.js and run it like so.
node scrape.js
As you can tell, we’re connecting to Bright Data’s scraping browser using the puppeteer.connect method by passing the browserWSEndpoint option. This option is the URL of the scraping browser which you can find in Bright Data’s dashboard.
You need to replace the USERNAME and PASSWORD with your own credentials. And the browser instance with the Host provided in the dashboard.
The best part is Bright Data provides a free trial of $5 if you want to try out their scraping browser. You can sign up for a free trial: Bright Data free trial
Using Bright Data’s scraping browser is ethical
It’s important to note here that when using Bright Data’s scraping browser, you don’t need to worry about the complaince since they maintains a compliance system that is based on deterrence, prevention, and enforcement. So, be sure that it’s fairly ethical to use it.
Wrapping up
So, this is how you can use Bright Data’s scraping browser to scrape web pages. As you can tell, it’s pretty straightforward and easy to use. You can also use it to scrape multiple websites at the same time by instantiating multiple scraping browser instances.

👋 Hi there! This is Amit, again. I write articles about all things web development. If you enjoy my work (the articles, the open-source projects, my general demeanour... anything really), consider leaving a tip & supporting the site. Your support is incredibly appreciated!


